没想到离上一篇文章发出已经过去半年时间了,惰性真的很严重,对这个小站算是撒手不管了。最近又有一些想要记载梳理的动力,打算从Java入手,围绕Java几个核心的知识点(例如面试中常常问到的问题)进行整理和记录。
今天就先围绕HashMap展开,说一说HashMap在Java中的一些思想。HashMap在Java8中得到了提升,引入了红黑树。本篇文章将基于Java6中的实现进行阐述。
在Java6中,HashMap是由数组和链表实现的。在阐述HashMap之前,先说说数组和链表的特点。
-
数组是连续存储的,占用内存严重,所以空间复杂度大。但数组的二分查找时间复杂度很小,为O(1)。数组的特点是:寻址容易,插入和删除困难。
-
而链表存储离散,占用内存宽松,空间复杂度小,但是时间复杂度为O(N)。链表的特点是:寻址困难,插入和删除容易。
那么HashMap其实是希望取两者之长,实现一个寻址容易,插入和删除也方便的数据结构。那其实这种结合数组和链表的实现方法被称为“拉链法“,可以简单理解为链表的数组。
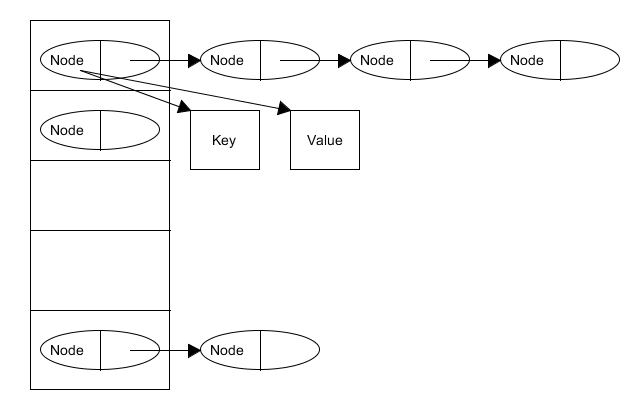
如上图所示,每个数组的元素存放的其实是一个链表的头节点。这个链表包含了Node
final int hash;
final K key;
V value;
Node<K,V> next;//下一个Node的引用
那么如何将每个Node放入到HashMap中呢?原理大致是:
-
先算出每个Node的Key对应的Hash,将Hash对数组长度取余,这个余数就是这个Node放置的数组index。
-
接着将该Node的next引用该位置上原有的那个Node(数组上存储的都是最后插入的元素),这样就完成一次put操作。
这种做法使用hash值来定位数组,这就引入了hash值的散列,能够尽量将Node均匀散列到不同的数组位置上,同时链表在空间上也是分散存储,这样就带来一个分散的存储好处。
参考: Java 6 API CSDN博文